Ускорители Blackwell от NVIDIA превзошли чипы H100 в тестах MLPerf Training 4.1 более чем в 2,2 раза, согласно информации The Register. NVIDIA утверждает, что повышенная пропускная способность памяти в Blackwell также сыграла свою роль. Тесты проводились на собственном суперкомпьютере NVIDIA Nyx на базе DGX B200.

Ускорители обладают примерно на 2,27 раза большей пиковой производительностью в вычислениях FP8, FP16, BF16 и TF32 по сравнению с последними моделями H100. B200 продемонстрировал на 2,2 раза более высокую производительность при настройке модели Llama 2 70B и удвоенную производительность при предварительном обучении модели GPT-3 175B. В случае рекомендательных систем и создания изображений увеличение составило 64 % и 62 % соответственно.
Компания также подчеркнула преимущества памяти HBM3e, использованной в B200, благодаря которой бенчмарк GPT-3 успешно прошёл на 64 ускорителях Blackwell без снижения производительности каждого графического процессора. В то же время для достижения такого же результата потребовалось бы 256 ускорителей H100. Однако компания не забыла и о Hopper — в рамках нового раунда компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100.
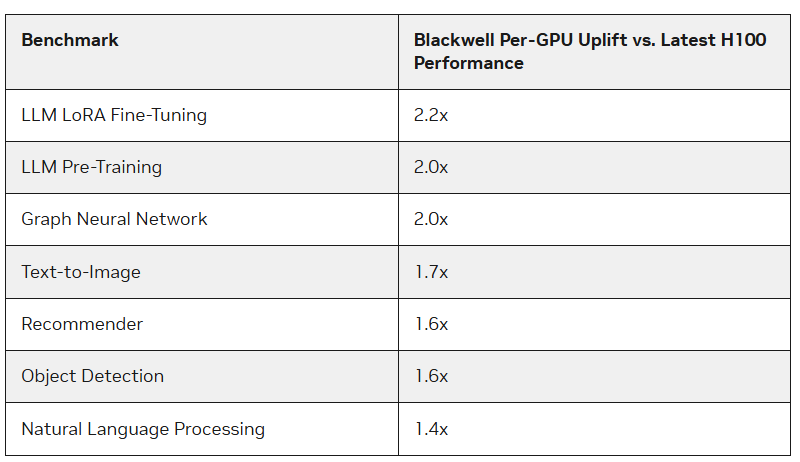
Компания обратила внимание на то, что платформа NVIDIA Blackwell обеспечивает значительное повышение производительности по сравнению с платформой Hopper, особенно при работе с LLM. Вместе с тем чипы поколения Hopper продолжают быть актуальными благодаря постоянным улучшениям программного обеспечения, которые иногда значительно повышают производительность в определённых задачах. Интересно то, что на этот раз NVIDIA решила не предоставлять результаты тестирования на платформе GB200, хотя такие системы есть и у самой компании, и у её партнёров.
В ответ Google опубликовала первые результаты тестирования шестого поколения TPU под названием Trillium, доступного с прошлого месяца, а также второй раунд результатов ускорителей пятого поколения TPU v5p. До этого Google тестировала только TPU v5e. Согласно данным от IEEE Spectrum, по сравнению с последней версией, Trillium демонстрирует увеличение производительности в 3,8 раза при обучении GPT-3.
Сравнивая результаты с показателями NVIDIA, картина уже не кажется такой радужной. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 минут, в то время как система с 11 616 ускорителями H100 справилась с задачей примерно за 3,44 минуты. При одинаковом количестве ускорителей решения Google отстают от решений NVIDIA почти в два раза, а разница между v5p и v6e составляет менее 10 %.
По результатам теста Stable Diffusion система из 1024 TPU v5p заняла второе место, выполнив задание за 2 минуты 44 секунды, в то время как система такого же размера на базе NVIDIA H100 справилась с задачей за 1 минуту 37 секунд. В других тестах на кластерах меньшего размера разница сохраняется примерно на уровне полутора раз. Однако Google подчёркивает масштабируемость и лучшее соотношение цены и производительности по сравнению с решениями конкурентов и предыдущими поколениями собственных ускорителей.
В рамках нового раунда MLPerf был представлен единственный результат измерения энергопотребления во время выполнения бенчмарка. Система, состоящая из восьми серверов Dell XE9680, каждый из которых содержит восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), при выполнении задачи тюнинга Llama2 70B использовала 16,38 миллиджоулей энергии и затратила на работу 5,05 минут. Средняя мощность составила 54,07 киловатт.
По материалам:
servernews