В популярных нынче вычислительных ядрах, процессорах и SoC, нацеленных на рынок машинного обучения, как правило, используются режимы вычисления с пониженной разрядностью, такие, как FP16 или даже INT8.
Но для реализации обучения и инференс-систем на периферии даже восьмибитная точность может быть избыточной, а вот экономичность остаётся ключевым фактором. Компания IBM раскрыла некоторые детали относительно своего нового ИИ-чипа, предназначенного специально для периферийных систем.
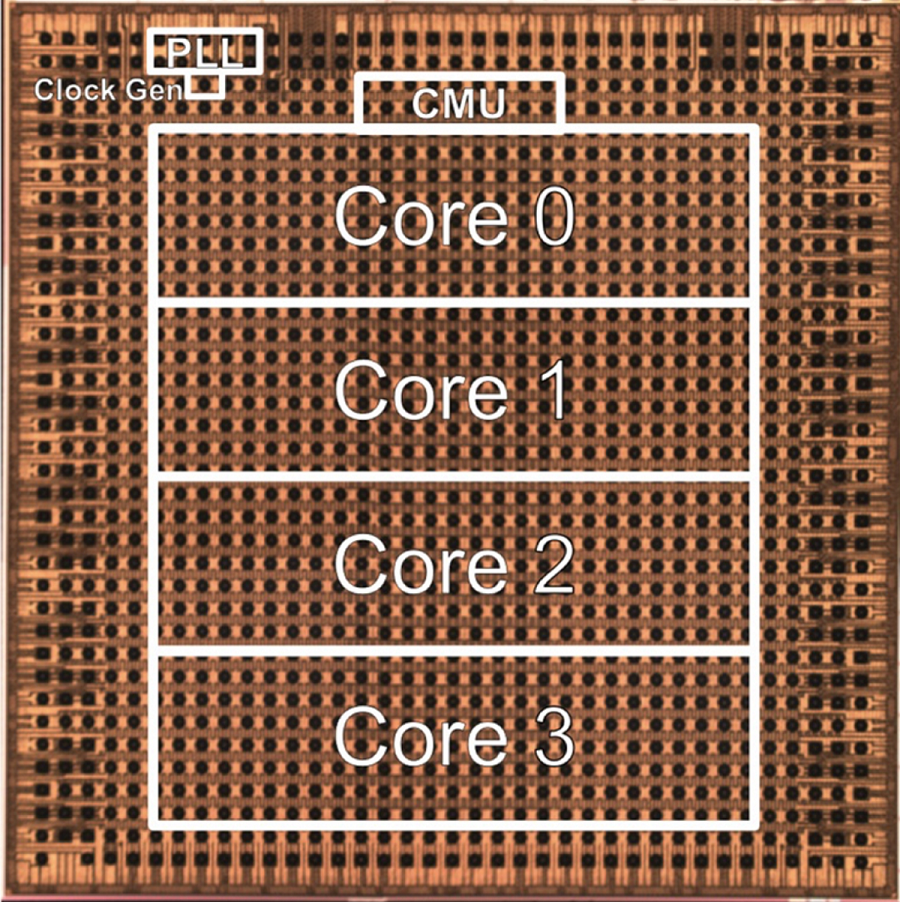
В последние годы наблюдается развитие так называемых периферийных вычислений, в которых первичная обработка потока «сырых» данных выполняется непосредственно в местах их получения, либо наиболее близко к таким местам. В отличие от классической обработки в ЦОД, на периферии такие ресурсы как габариты и энергоснабжение ограничены, вот почему разработчики стараются сделать такие чипы и системы как можно более экономичными и компактными.
Среди них компания IBM, которая раскрыла информацию о новом прототипе ИИ-сопроцессора, предназначенном специально для систем машинного обучения и инференс-систем периферийного типа. Как сообщают источники, главным преимуществом новинки является способность выполнять вычисления с ещё менее высокой точностью, чем принято в машинном обучении, однако достаточной для ряда задач.
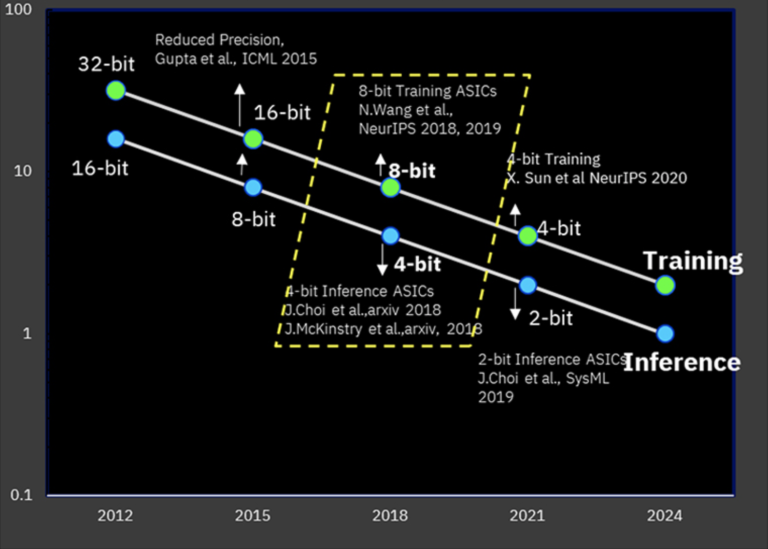
Изначально в машинном обучении применялись классические вычислительные ядра с точностью вычислений как минимум FP32, однако для ряда случаев такая точность избыточна, а энергопотребление далеко от оптимального. В этом смысле за прошедшие пять лет именно IBM удалось добиться существенных успехов. Ещё в 2019 году компания показала возможность использования 8-битной точности с плавающей запятой для обучения, а для инференса оказалось достаточно даже 4 бит.
На конференции NeurIPS 2020 компания отчиталась о дальнейших успехах в этой области: новый периферийный ИИ-сопроцессор, спроектированный с использованием 7-нм технологических норм, обеспечивает достаточно надёжные результаты при обучении в 4-битном режиме, а для инференс-задач он использует и вовсе двухбитный режим. Точность при этом достаточно высока, хотя в некоторых случаях и понижается на несколько процентов, а вот производительность оказывается почти в четыре раза выше, нежели при использовании 8-битного режима. Естественно, возможны и вычисления смешанной точности.
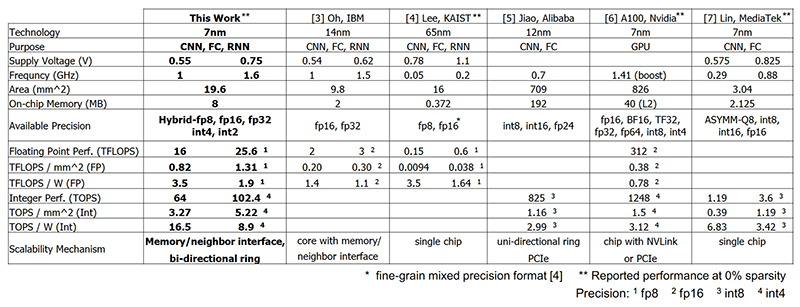
За счёт сочетания пониженной точности и тонкого техпроцесса обеспечивается высокая энергоэффективность, и IBM не без оснований считает, что такие процессоры займут место классических там, где их возможностей достаточно, например, в машинном зрении и системах распознавания речи. Кроме того, IBM разработала новый алгоритм сжатия ScaleCom, позволяющий очень эффективно сжимать именно данные машинного обучения. Говорится о возможности сжатия в 100, а в некоторых случаях и в 400 раз. Подробности можно узнать на сайте компании.