Компания GigaIO анонсировала HPC-систему SuperNODE, предназначенную для решения ресурсоёмких задач в области генеративного ИИ. SuperNODE позволяет связать воедино до 32 ускорителей посредством компонуемой платформы GigaIO FabreX. Архитектура FabreX на базе PCI Express, по словам создателей, намного лучше InfiniBand и NVIDIA NVLink по уровню задержки и позволяет объединять различные компоненты — GPU, FPGA, пулы памяти и пр.

SuperNODE даёт возможность более эффективно использовать ресурсы, нежели в случае традиционного подхода с ускорителями в составе нескольких серверов. В частности для SuperNODE доступны конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100 с хранилищем ёмкостью до 1 Пбайт. При этом платформа компактна, энергоэффективна (до 7 кВт) и не требует дополнительной настройки перед работой.
Поскольку приложения с большими языковыми моделями требуют огромных вычислительных мощностей, технологии, которые сокращают количество необходимых обменов данными между узлом и ускорителем, имеют решающее значение для обеспечения необходимой скорости выполнения операций при снижении общих затрат на формирование инфраструктуры. Что немаловажно, платформ, по словам разработчиков, демонстрирует хорошую масштабируемость производительности при увеличении числа ускорителей.
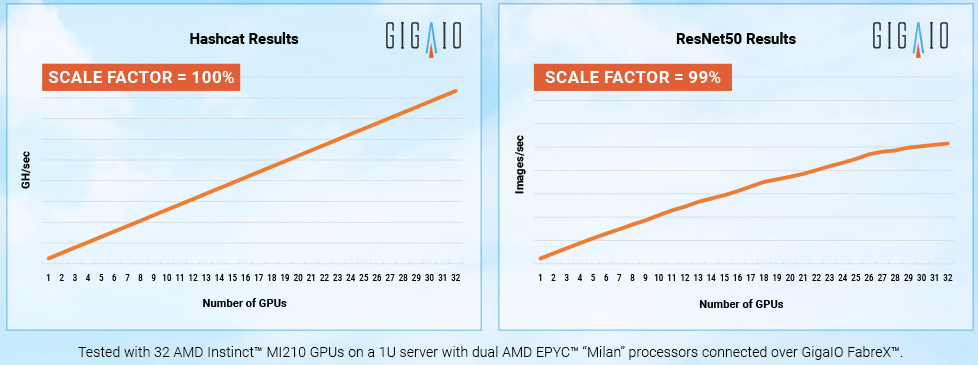
«Система SuperNODE, созданная GigaIO и работающая на ускорителях AMD Instinct, обеспечивает привлекательную совокупную стоимость владения как для традиционных рабочих нагрузок HPC, так и для задач генеративного ИИ», — сказал Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер по дата-центрам AMD. Стоит отметить, что у AMD нет прямого аналога NVIDIA NVLink, так что для объединение ускорителей в большие пулы с высокой скоростью подключения возможно как раз с использованием SuperNODE.
Источник servernews