Компания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных.
До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании.
Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений.
Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков.
Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно.
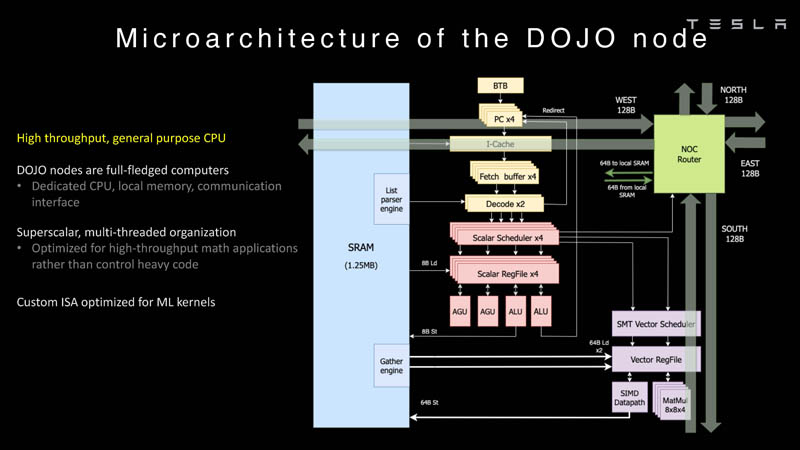
Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно.
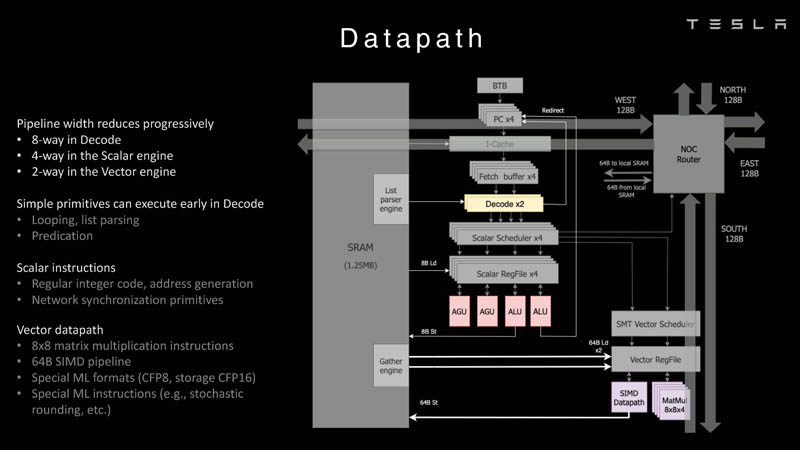
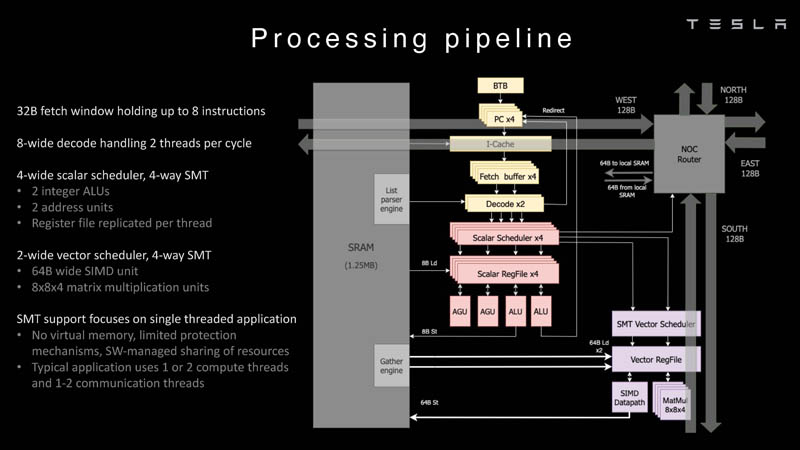
Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО.
64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4).
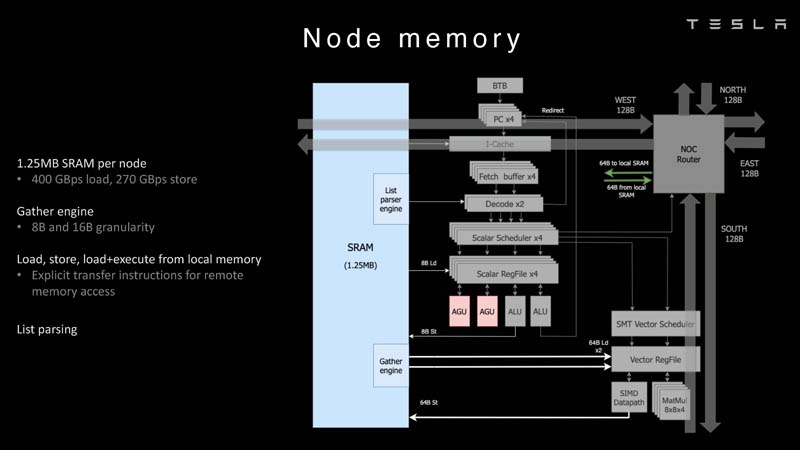
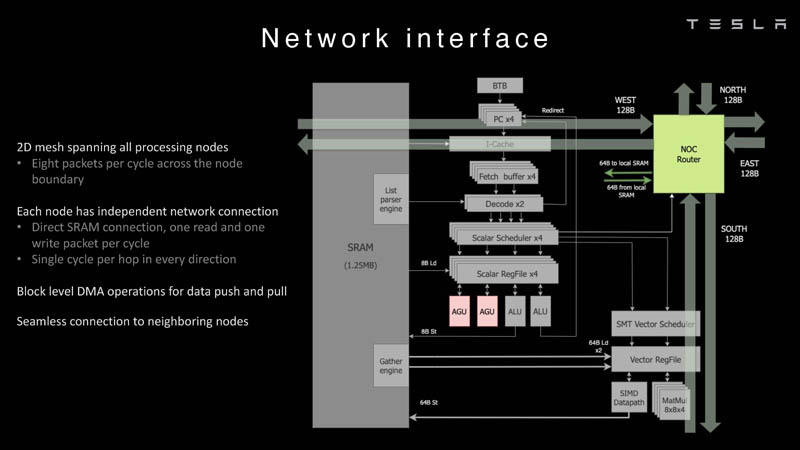
У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.

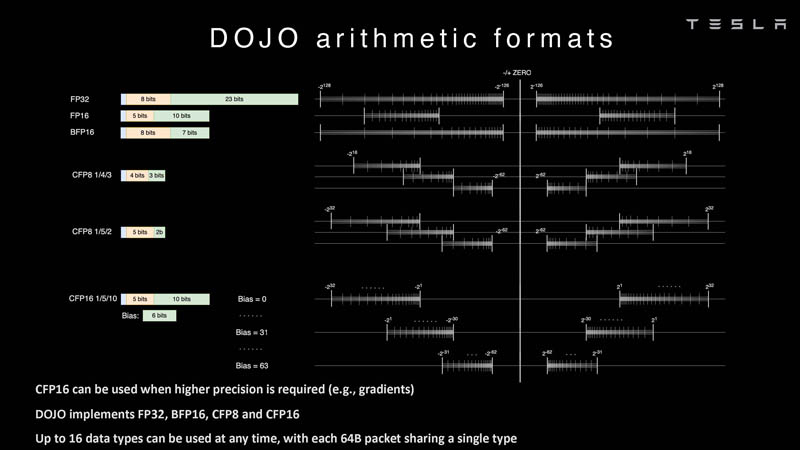
Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.

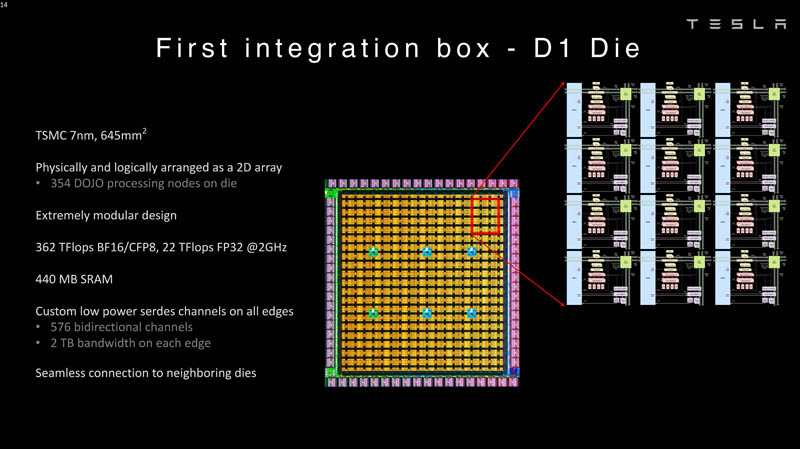
Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.

Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании.
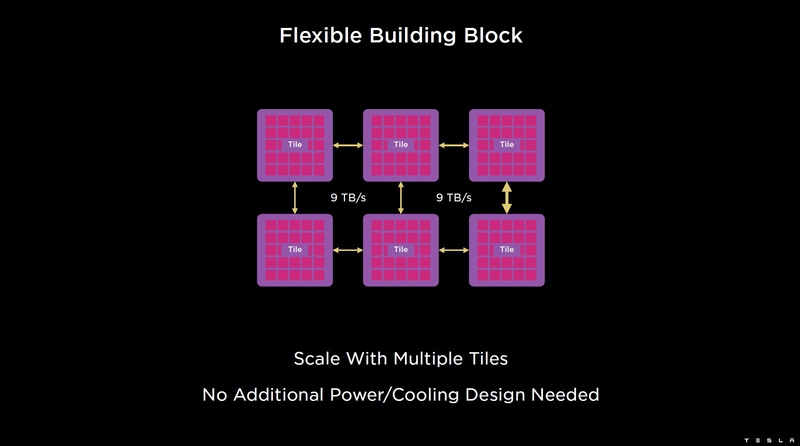
Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 8 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile.
Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.

Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3).
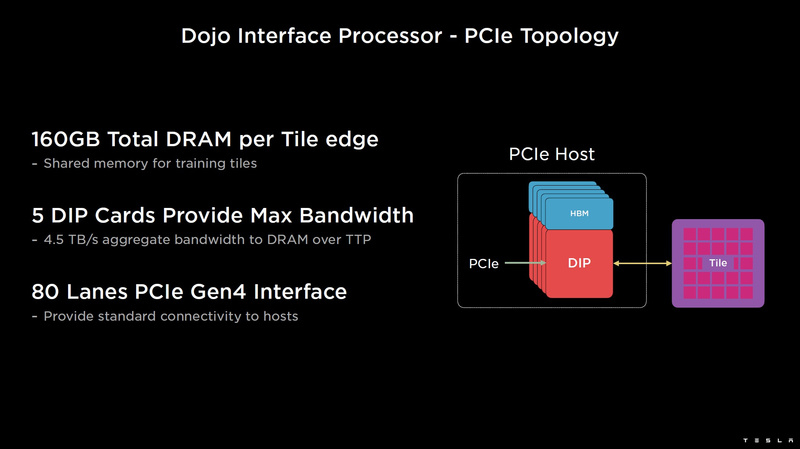
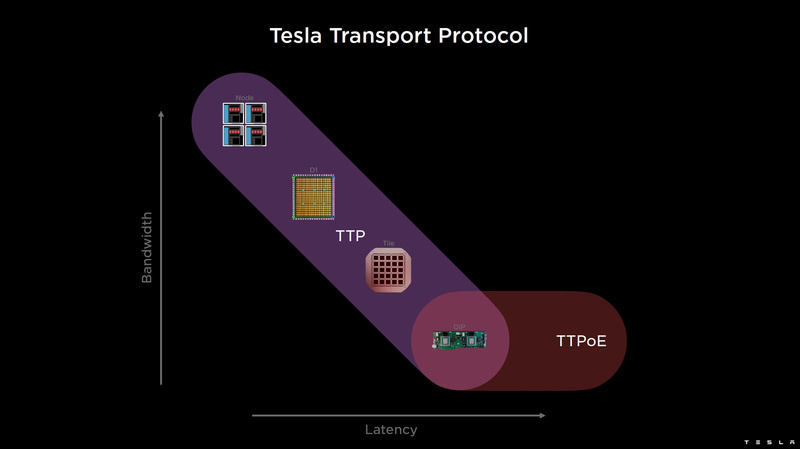
DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.

В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее.
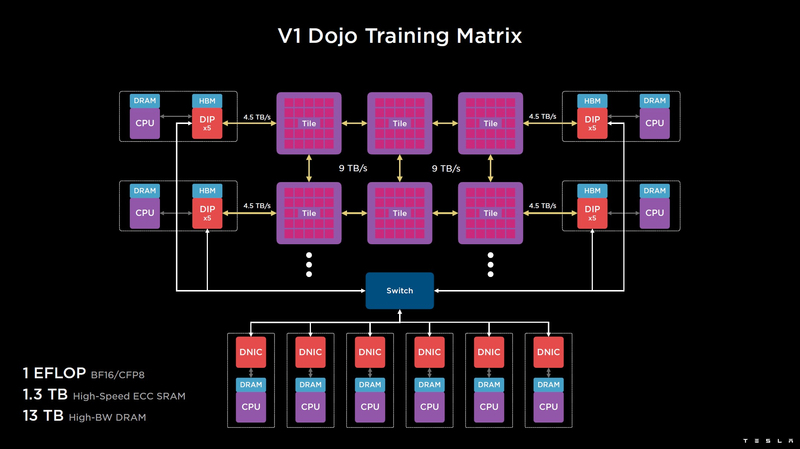
В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс.
Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
Источник servernews