Гибридный ускоритель NVIDIA Grace Hopper состоит из CPU- и GPU-модулей, связанных интерконнектом NVLink C2C. Однако, согласно информации от HPCWire, в структуре и работе суперчипа есть некоторые особенности, описанные шведскими учёными.
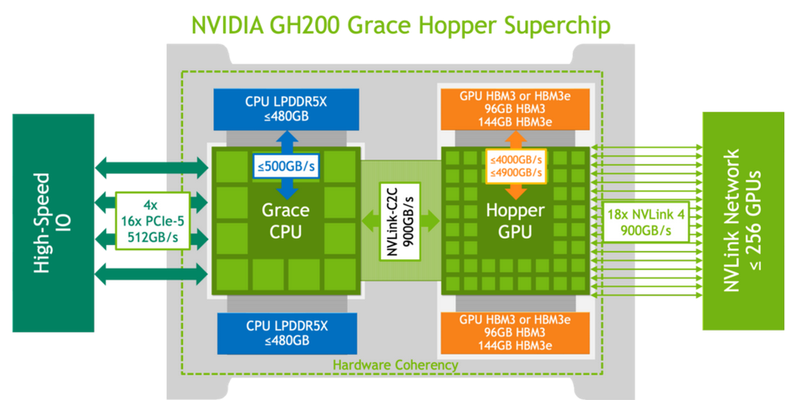
Они измерили производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных условиях, чтобы сравнить полученные результаты с заявленными характеристиками NVIDIA. Изначально для интерконнекта была указана скорость 900 ГБ/с, что в 7 раз превышает возможности PCIe 5.0. Графическая память HBM3 обеспечивает пропускную способность до 4 ТБ/с, а версия с HBM3e — до 4,9 ТБ/с. Процессорная часть (Grace) использует LPDDR5x с пропускной способностью до 512 ГБ/с.
Исследователи получили базовую версию Grace Hopper с 480 ГБ LPDDR5X и 96 ГБ HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В тесте STREAM были получены следующие показатели пропускной способности: 486 ГБ/с для CPU и 3,4 ТБ/с для GPU, что близко к заявленным характеристикам. Однако скорость NVLink-C2C составила только 375 ГБ/с в направлении host-to-device и 297 ГБ/с в обратном направлении. В итоге получается 672 ГБ/с, что значительно отличается от заявленных 900 ГБ/с (75% от теоретического максимума).
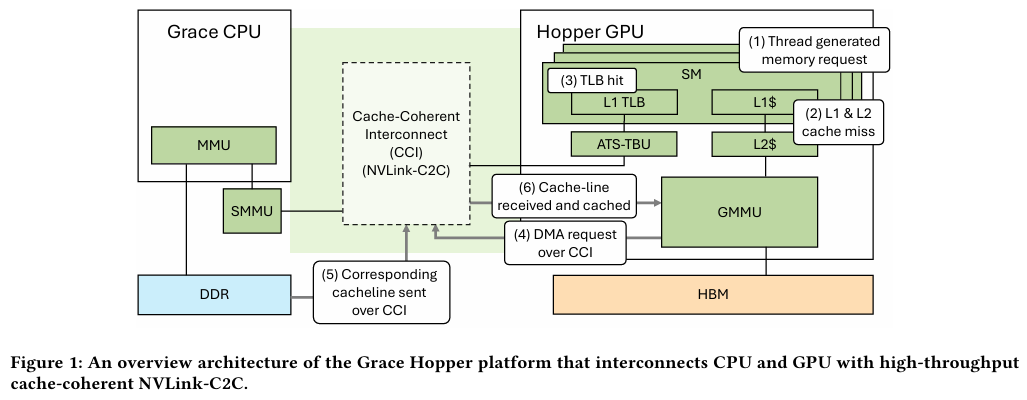
Благодаря своей конструкции, Grace Hopper предлагает два типа таблиц для страниц памяти: общесистемную (страницы размером 4 КБ или 64 КБ по умолчанию), охватывающую CPU и GPU, и предназначенную исключительно для GPU-части (2 МБ). Скорость инициализации зависит от источника запроса. Если инициализация памяти происходит на стороне CPU, данные по умолчанию сохраняются в LPDDR5x, к которому GPU-часть получает прямой доступ через NVLink C2C (без миграции), и таблица памяти становится видимой для GPU и CPU.
Когда управление памятью осуществляется не операционной системой, а CUDA, инициализацию можно сразу выполнить на стороне графического процессора, что обычно происходит быстрее. Данные размещаются в HBM. Создаётся единое виртуальное адресное пространство, однако существуют две таблицы памяти: для центрального и графического процессоров. Обмен данными между ними происходит с использованием механизма миграции страниц. Несмотря на наличие NVLink C2C, наиболее эффективной является ситуация, когда объёма HBM достаточно для обработки нагрузки на графическом процессоре, а LPDDR5x предоставляет достаточную пропускную способность для обработки нагрузки на центральном процессоре.
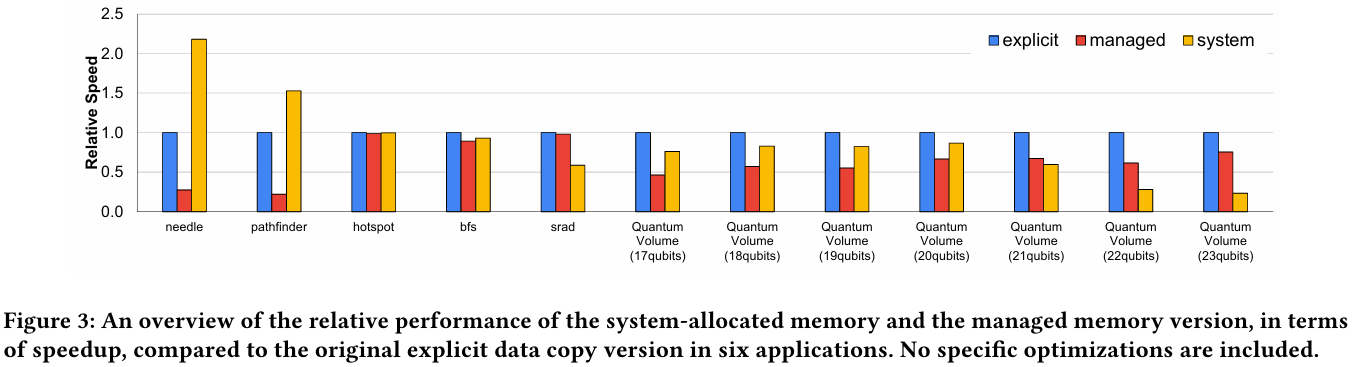
Исследователи также рассмотрели вопрос производительности при использовании страниц памяти разного размера. Страницы по 4 КБ обычно используются процессорной частью с LPDDR5X, а также когда GPU требуется получить данные от CPU через NVLink-C2C. Однако для HPC-нагрузок предпочтительнее использовать страницы по 64 КБ, так как управление ими требует меньше ресурсов. При хаотичном и непостоянном доступе к памяти страницы по 4 КБ обеспечивают более гибкое управление ресурсами. В некоторых случаях двойное преимущество в производительности достигается благодаря отсутствию перемещения неиспользуемых данных на страницах по 64 КБ.
В опубликованной работе подчёркивается необходимость дальнейших исследований для более глубокого понимания механизмов работы унифицированной памяти в гетерогенных решениях, таких как Grace Hopper.
По материалам:
servernews